
最近我准备做一个AI Agent项目。既然是 Agent,就必须有“长期记忆”。这就意味着,我得找个地方存向量数据。
按照我过去的习惯,我会选择 MySQL。但是Mysql其实并不适合agent项目。
为什么不用 MySQL?
如果用 MySQL,事情会变得很麻烦。
MySQL 原生对向量检索的支持很弱。如果坚持用 MySQL,我的架构就会变成这样:
MySQL+一个向量数据库。
太重了!
引入两个数据库,就意味着我要处理数据同步(这太臃肿了)。
例如一边插入文本,另一边存入向量。如果中间网络抖动,就很容易出现数据不一致。
所以,我选择了PostgreSQL。
PostgreSQL 到底是个啥?有什么神仙功能?
他其实就是一个免费的对象-关系数据库,是开源的,在全球数据库榜单上位列第四,甚至还在持续增长。
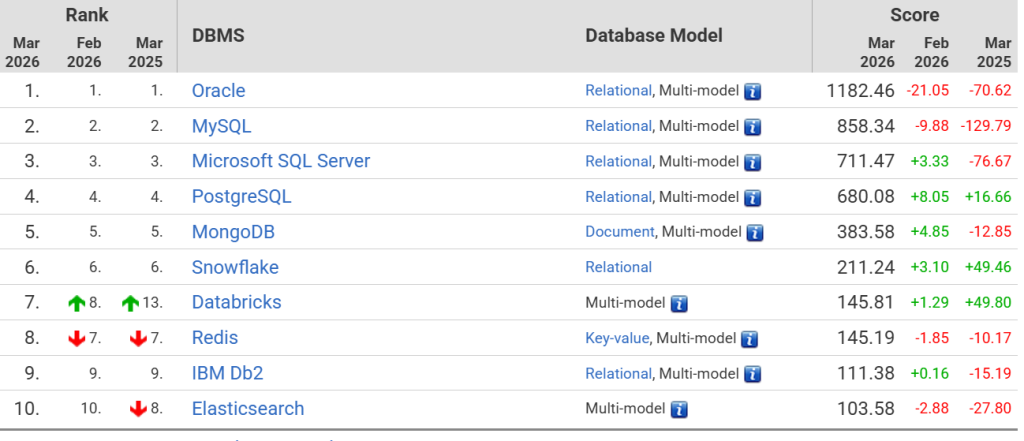
PG与Mysql的区别或者说优势是什么?
- 在SQL实现上要比Mysql完善
- 对表连接支持较完整,支持索引类型很多,复杂查询能力较强
- PG主表采用堆表存放,Mysql采用索引组织表,能够支持比Mysql更大的数据量
- PG的主备复制属于物理复制,相当于Mysql的基于binlog的逻辑复制,数据的一致性更加可靠,复制性能更高
- 支持JSON和其他NoSQL功能
- 完全免费,如果你把PGSQL改一改,然后再拿去卖钱,也没有人管你,这一点很重要
它还有几个杀手锏:
- 极度自由的插件生态:这是重点!装个 PostGIS 插件,它就能做地图地理位置计算;装个 pgvector 插件,它瞬间就能变成一个专业的向量数据库。
- 原生的 JSON/JSONB 支持:LLM 经常会返回一堆结构不固定的 JSON 格式配置。在 PG 里,你可以直接把 JSON 塞进去,甚至能在 JSON 的内部字段上建索引。简直可以当半个 MongoDB 来用。
为什么做Agent项目需要用他?
All in One。
只需要使用PG + pgvector就可以完成Agent相关的所有需求,业务数据和向量数据都在一张表里。
怎么用?
前提条件:需要docker环境
Docker 快速安装 PostgreSQL + PGvector
打开终端,直接复制并运行下面这段命令(注意修改 -v 挂载目录为你本地的实际路径)
docker run -d \
--name my_pgvector \
-p 5432:5432 \
-e POSTGRES_PASSWORD=123456 \
-v /Users/guide/docker/postgresql/data:/var/lib/postgresql/data \
pgvector/pgvector:pg17一般使用pgvertor需要手动用sql开启插件。但是Spring AI已经帮我们开启了。
通常情况下,用 PG 的向量功能,你需要先进数据库,手动敲一句:CREATE EXTENSION vector
但是!如果你看一眼 Spring AI 的底层源码,你会发现它把脏活累活全包了!
/**
* PgVectorStore 实现了 InitializingBean 接口。
* Spring 容器在完成 Bean 的属性注入后,会自动调用 afterPropertiesSet() 方法。
*/
public class PgVectorStore extends AbstractObservationVectorStore implements InitializingBean {
@Override
public void afterPropertiesSet() {
// 1. 打印初始化日志,确认当前操作的表名和 Schema 名
logger.info("Initializing PGVectorStore schema for table: {} in schema: {}",
this.getVectorTableName(), this.getSchemaName());
logger.info("vectorTableValidationsEnabled {}", this.schemaValidation);
// 2. 校验逻辑:如果开启了校验,则检查数据库中现有的表结构是否符合要求
if (this.schemaValidation) {
this.schemaValidator.validateTableSchema(this.getSchemaName(), this.getVectorTableName());
}
// 3. 初始化开关:如果 initializeSchema 为 false,则跳过后续的所有建表和安装插件操作
// 这通常用于生产环境,由 DBA 手动预先创建好环境
if (!this.initializeSchema) {
logger.debug("Skipping the schema initialization for the table: {}", this.getFullyQualifiedTableName());
return;
}
// --- 数据库底层环境准备 ---
// 4. 安装 pgvector 插件:这是实现向量检索的核心扩展
this.jdbcTemplate.execute("CREATE EXTENSION IF NOT EXISTS vector");
// 5. 安装 hstore 插件:用于支持键值对存储(通常作为 metadata 的补充)
this.jdbcTemplate.execute("CREATE EXTENSION IF NOT EXISTS hstore");
// 6. 安装 UUID 插件:如果主键类型配置为 UUID,则需要安装此扩展来生成随机 ID
if (this.idType == PgIdType.UUID) {
this.jdbcTemplate.execute("CREATE EXTENSION IF NOT EXISTS \"uuid-ossp\"");
}
// 7. 创建数据库 Schema(命名空间),默认为 "public"
this.jdbcTemplate.execute(String.format("CREATE SCHEMA IF NOT EXISTS %s", this.getSchemaName()));
// --- 表结构处理 ---
// 8. 危险操作:如果配置了 removeExistingVectorStoreTable 为 true,则先删除旧表
// 警告:这会导致数据丢失,通常仅用于集成测试环境
if (this.removeExistingVectorStoreTable) {
this.jdbcTemplate.execute(String.format("DROP TABLE IF EXISTS %s", this.getFullyQualifiedTableName()));
}
// 9. 创建向量存储核心表
// id: 主键,类型根据 getColumnTypeName() 动态决定(如 uuid, serial 等)
// content: 原始文本内容
// metadata: 关联的元数据,存储为 JSON 格式
// embedding: 向量字段,指定维度 vector(N)
this.jdbcTemplate.execute(String.format("""
CREATE TABLE IF NOT EXISTS %s (
id %s PRIMARY KEY,
content text,
metadata json,
embedding vector(%d)
)
""",
this.getFullyQualifiedTableName(),
this.getColumnTypeName(),
this.embeddingDimensions()));
// --- 性能优化:索引 ---
// 10. 创建向量索引:提高相似度搜索的效率
// 如果 createIndexMethod 不是 NONE(如 HNSW 或 IVFFlat),则执行创建索引语句
if (this.createIndexMethod != PgIndexType.NONE) {
this.jdbcTemplate.execute(String.format("""
CREATE INDEX IF NOT EXISTS %s ON %s USING %s (embedding %s)
""",
this.getVectorIndexName(), // 索引名称
this.getFullyQualifiedTableName(), // 表名
this.createIndexMethod, // 索引算法(如 hnsw)
this.getDistanceType().index // 距离度量函数(如 vector_cosine_ops 等)
));
}
}
// ... 其他方法
}看看PgVectorStore这个类的源码,它实现了InitializingBean接口。这意味着Spring容器启动时,会自动执行afterPropertiesSet()方法。
在这个方法里,Spring AI 悄悄帮你干了下面这些事:
- 自动安装核心插件:它会自动调用jdbcTemplate执行CREATE EXTENSION IF NOT EXISTS vector。不仅如此,连用来存元数据的hstore插件,和生成主键的uuid-ossp插件都帮你装好了。
- 自动建表:它会动态拼装 SQL,建好包含 id、content、metadata json(元数据)和embedding vector(N)(向量字段)的核心存储表。
- 自动建向量索引:SpringAI会自动帮你创建向量索引来提高查询效率。
总结一下
总之Postgresql是一个功能极其强大的数据库,mysql能做的不能做的他都能实现,我认为,尤其在这个ai的时代,他肯定会发光发热。





