
当你在搜索引擎搜索东西的时候,你会发现会显示出满足你所输入的前缀的提示,是由什么算法实现的呢,是前缀树,本篇文章来详解前缀树。
为什么我们需要前缀树?
先来看看如果不用前缀树的话,用其他方式譬如数组,哈希表等的缺点。
- 数组/链表:可以实现前缀搜索的功能,但是时间复杂度很高,你需要遍历所有的数据,这是不可接受的。
- 哈希表:根本就不能实现前缀搜索的功能,只能够实现精准匹配。
此刻,前缀树闪亮登场,它能够实现前缀搜索并且时间复杂度较低。
什么是前缀树?
前缀树本质上是一棵多叉树(也叫n叉树),其大多数情况是和后缀树一起讨论的。
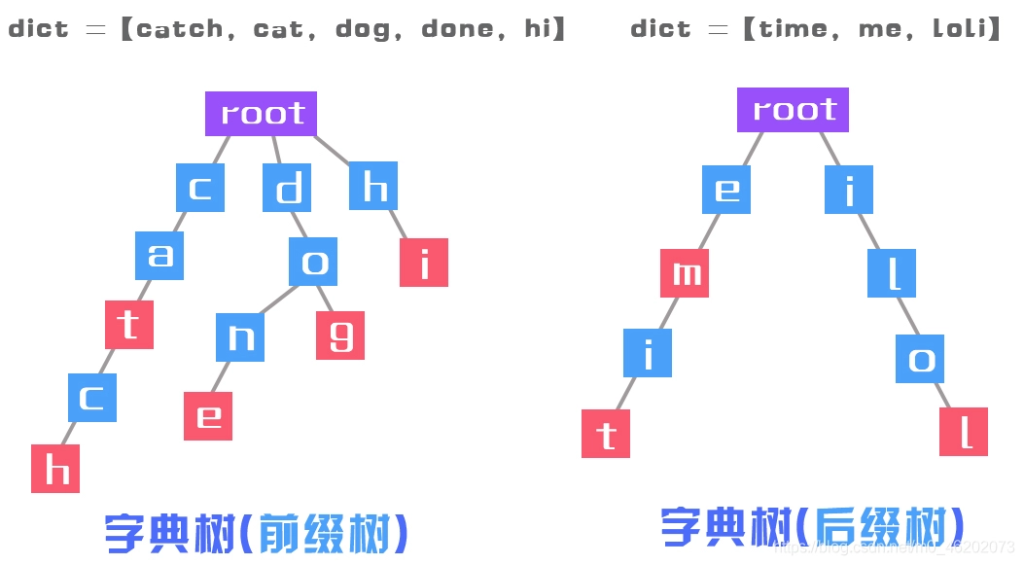
就如上图所示,我们向前缀树插入catch,cat,dog,done,hi可以看cat和catch,cat是他们的共同前缀,可以看见cat的结尾t和catch的结尾h是被红色标记的,代表着这是一个单词的结尾。dog和done,do是他们的共同前缀o之后走向不同的路径。
核心代码实现(Java)
要实现前缀树,首先要定义一个TrieNode类,一般包含两个属性。
- 子节点列表: 如果只包含小写字母,可以用长度为 26 的数组 TrieNode[] children;如果是全字符,可以用 HashMap<Character, TrieNode>。
- 结束标志: 一个布尔值 isEnd,标记该节点是否是一个单词的结尾(比如上面的t单词,虽然还有子节点 c,但cat本身也是个完整的词,所以 isEnd = true)。
class TrieNode {
TrieNode[] children; // 指向子节点的指针数组
boolean isEnd; // 是否是单词的结尾
public TrieNode() {
children = new TrieNode[26]; // 假设只有 26 个小写英文字母
isEnd = false;
}
}完整的Trie类的实现通常包括包含三个核心操作:insert(插入)、search(全词查找)、startsWith(前缀查找)。
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode(); // 初始化根节点
}
// 1. 插入单词
// 时间复杂度:O(L),L 为单词长度
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int index = c - 'a'; // 计算字母的索引 (0-25)
if (node.children[index] == null) {
node.children[index] = new TrieNode(); // 如果没有该子节点,新建一个
}
node = node.children[index]; // 节点下移
}
node.isEnd = true; // 单词遍历完,标记为词尾
}
// 2. 查找单词(完全匹配)
// 时间复杂度:O(L)
public boolean search(String word) {
TrieNode node = searchPrefix(word);
return node != null && node.isEnd; // 必须匹配到结尾,且 isEnd 为 true
}
// 3. 查找前缀
// 时间复杂度:O(L)
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null; // 只要能走完前缀路径即可
}
// 辅助方法:沿着树向下提取前缀节点
private TrieNode searchPrefix(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
int index = c - 'a';
if (node.children[index] == null) {
return null; // 路径断了,说明前缀不存在
}
node = node.children[index];
}
return node; // 返回最后一个字符对应的节点
}
}前缀树的优缺点与复杂度分析
优点:
- 查询速度极快:无论是插入还是查询,时间复杂度都是O(N),这与字典库中有多少个单词无关。
- 原生前缀查询:前缀树实现前缀是原生支持的,哈希表只能精准匹配。
是不是前缀树就没有缺点呢?当然不是,不然为什么不全用前缀树呢?
缺点:
- 极其耗费内存(空间换时间): 每个节点都要保存一个长度为 26 的指针数组。如果字符串前缀重合度极低,会导致大量的内存浪费。
- 缓存不友好: 哈希表在内存中可以做到紧凑分布,而前缀树的节点在内存中是分散分配的,这会导致 CPU 缓存命中率下降。
总结
前缀树(Trie)是一种典型用空间换时间的数据结构。适用于搜索引擎,超多文件的前缀查询等操作,核心思想是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。






小弟弟你挺牛逼克拉斯啊
😍
我无敌!